UKURAN GEJALA PUSAT DATA DIKELOMPOKKAN
UKURAN
GEJALA PUSAT DATA DIKELOMPOKKAN
a. Mean
(Rata – Rata Hitung)
Dalam istilah sehari – hari, mean dikenal dengan
sebutan angka rata – rata, ada dua macam mean yang di bicarakan yaitu : mean
untuk data yang tidak dikelompokkan dan mean untuk data yang
dikelompokan. Mean adalah total semua data dibagi jumlah data. Mean
digunakan ketika data yang kita miliki memiliki sebaran normal atau mendekati
normal (berbentuk setangkup, nilai yang paling banyak berada ditengah dan makin
besar semakin sedikit, makin kecil makin sedikit pula, nilai-nilai ekstrim yang
besar maupun yang kecil hampir tidak ada).
Rata-rata Hitung :

b. Median
(Nilai Tengan)
Ukuran pemusatan yang menempati posisi tengah jika
data diurutkan menurut besarnya. Median adalah nilai yang berada
ditengah-tengah data setelah diurutkan dari yang terkecil sampai terbesar.
Median cocok digunakan bila data yang kita miliki tidak menyebar normal atau
memiliki nilai yang berbeda-beda secara signifikan.
Median :

c. Modus
(Data Yang Sering Muncul)
Modus adalah suatu angka atau bilangan yang paling
sering terjadi / muncul tetapi kalo pada data distribusi frekuensi
interval modus terletak pada frekuensi yang paling besar.
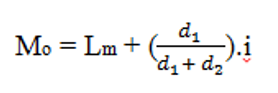
d. Kuartil
Kuartil adalah suatu harga yang membagi histogram
frekuensi menjadi 4 bagian yang sama, sehingga disini akan terdapat 3
harga kuartil yaitu kuartil I ( K1), kuartil II (K2) dan kuartil III (K3),
dimana harga kuarti II sama dengan harga median.

e. Desil
Untuk kelompok data dimana n ≥ 10, dapat ditentukan 9
nilai bagian yang sama, misalnya D1, D2, … Q9, artinya setiap bagian mempunyai
jumlah observasi yang sama, sedemikian rupa sehingga nilai 10% data/observasi
sama atau lebih kecil dari D1, nilai 20% data/observasi sama atau lebih kecil
dari D2, dan seterusnya. Nilai tersebut dinamakan desil pertama, kedua dan
seterusnya sampai desil kesembilan.
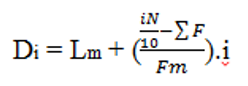
f. Persentil
Untuk kelompok data dimana n ≥ 100, dapat ditentukan
99 nilai, P1, P2, … P99, yang disebut persentil pertama, kedua dan ke-99, yang
membagi kelompok data tersebut menjadi 100 bagian,masing-masing mempunyai
bagian dengan jumlah observasi yang sama, dan sedemikian rupa sehingga 1%
data/observasi sama atau lebih kecil dari P1, 2% data/observasi sama atau lebih
kecil dari P2.

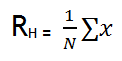

Komentar
Posting Komentar